
※訳注:この記事は、記事投稿サイトMediumに5/4に投稿された記事を翻訳したものです。

「ありえない!!!!」
このタイトルを読んだ、あなたの感想はこんな感じかと思います。
しかしこの記事を読み進めていけば、無料(!)のソフトウェアプラットフォームを使ってプログラミングをすることなく、ディープラーニングのモデルの設計・開発・トレーニングができる新しい方法を体験することができるでしょう。
私がディープラーニングを学び始めてからずっと、Quoraなどで
「自分が良いプログラマーでなくても、ディープラーニングを学習することは可能か?」
「AIやディープラーニングを、プログラミングの知識なしに学習できるのか?」
という質問と、それに対する明確な「いいえ」という回答のやりとりをたくさん見てきました。
しかし、もし私が同じ質問に答えるなら、答えは「はい」です。
Deep Cognition社が出している「Deep Learning Studio(ディープラーニングスタジオ)」という最も簡単なディープラーニング用のプラットフォームを使えば可能なのです。

ディープラーニングスタジオは、2017年1月からビジュアルインターフェースの稼働が始まった、2つのバージョン(クラウドおよびデスクトップ)で使用できる、初めての安定したディープラーニングプラットフォームです。
このプラットフォームは、データ処理やモデルの開発、トレーニング、デプロイ、管理において総合的なソリューションを提供してくれます。
ディープラーニングスタジオを使うことにより、開発者及び、これからエンジニアや研究者を目指す人なら誰でもディープラーニングのソリューションを素早く開発してデプロイすることが可能です。
また、TensorFlow,やMXNet、Kerasとの安定的な統合も可能です。
・・・
今ここでディープラーニングスタジオについての全てを説明するよりも、実際にどのように動くのかデモしたほうが良いでしょう。
「人に教えるのなら実際にやってみるべきだ」ということわざもありますし、Deep Cognition社のCEOであり共同設立者であるMandeep Kumar(マンディープ・クマール)も同じことを言っています。
彼はディープラーニングスタジオを使ってCTスキャンのデータセットに3Dの脳回神経回路を適用するための実際の方法を、Kaggleに投稿しています。
その各ステップは以下の通りです。
Step-1: アクセスする
以下のリンクから、ディープラーニングスタジオにアクセスしてサインアップします。
※非常に重要なポイント:
Deep Cognition社のサイト上で無料のアカウント登録をすると、NVIDIAのGPUトレーニングが2時間無料で受講可能です。これは非常に魅力的な特典です。
Step-2: キャッシュデータセットを有効化する
次に、Kaggleのアカウントからダウンロードした2つの小さなファイルをアップロードすることにより、自身のアカウントのキャッシュデータセットを有効化します。
これらのファイルをアップロードすることで、Kaggleのデータセットへのアクセスが可能になります。
(下記の図の、黄色でマークされている1〜4の順に沿ってください。)
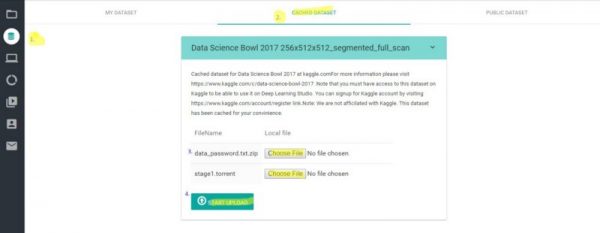
図1
Step-3: 新規プロジェクトを作成して開く
新規プロジェクトを作成します。左のプロジェクトメニューに行き、+ボタンを押します。
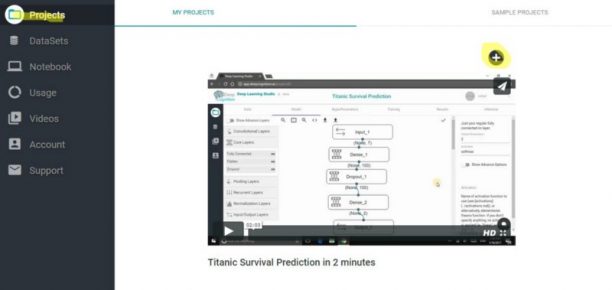
図2
プロジェクトの名前と概要を入力して、プロジェクトバーにある四角で囲まれた矢印のアイコンをクリックしてプロジェクトを開きます。
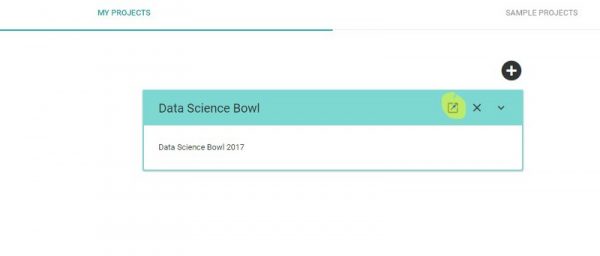
図3
Step-4: データセットを選択して一連のトレーニング/検証 を行う
このデモでは、1,200のサンプルを使ったトレーニングを行い197のサンプルを使った検証を行っています。
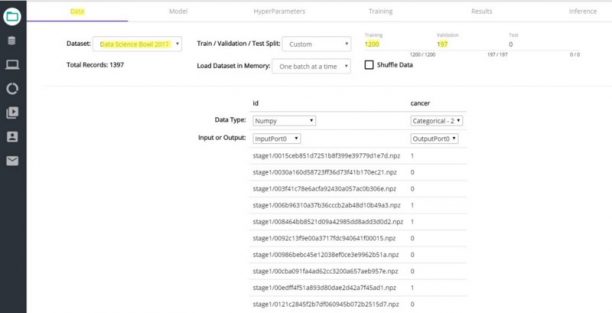
図4
Step-5: モデルを作成する
データセットを選択した後は、「Modelタブ」をクリックしてモデルの構築をします。
下記の図のように、左のメニューバーからキャンバスへレイヤーをドラッグして、レイヤーのブロックを繋ぎます。
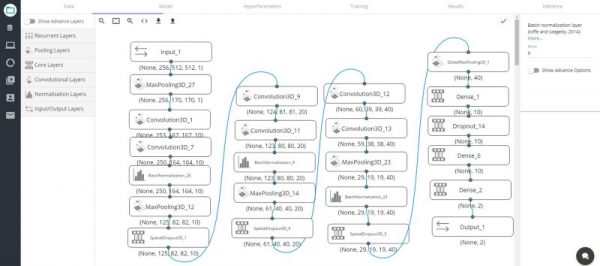
図5
下記のコードはディープラーニングスタジオで作った図5のモデル全体を実際のソースコードで示したもので、これはMandeep Kumarが作ったものです。
def get_model(): Input_1 = Input(shape=(256, 512, 512, 1)) MaxPooling3D_27 = MaxPooling3D(pool_size= (1,3,3))(Input_1) Convolution3D_1 = Convolution3D(kernel_dim1= 4,nb_filter= 10,activation= 'relu' ,kernel_dim3= 4,kernel_dim2= 4)(MaxPooling3D_27) Convolution3D_7 = Convolution3D(kernel_dim1= 4,nb_filter= 10,activation= 'relu' ,kernel_dim3= 4,kernel_dim2= 4)(Convolution3D_1) BatchNormalization_28 = BatchNormalization()(Convolution3D_7) MaxPooling3D_12 = MaxPooling3D(pool_size= (2,2,2))(BatchNormalization_28) SpatialDropout3D_1 = SpatialDropout3D(p= 0.5)(MaxPooling3D_12) Convolution3D_9 = Convolution3D(kernel_dim1= 2,nb_filter= 20,activation= 'relu' ,kernel_dim3= 2,kernel_dim2= 2)(SpatialDropout3D_1) Convolution3D_11 = Convolution3D(kernel_dim1= 2,nb_filter= 20,activation= 'relu' ,kernel_dim3= 2,kernel_dim2= 2)(Convolution3D_9) BatchNormalization_9 = BatchNormalization()(Convolution3D_11) MaxPooling3D_14 = MaxPooling3D(pool_size= (2,2,2))(BatchNormalization_9) SpatialDropout3D_4 = SpatialDropout3D(p= 0.5)(MaxPooling3D_14) Convolution3D_12 = Convolution3D(kernel_dim1= 2,nb_filter= 40,activation= 'relu' ,kernel_dim3= 2,kernel_dim2= 2)(SpatialDropout3D_4) Convolution3D_13 = Convolution3D(kernel_dim1= 2,nb_filter= 40,activation= 'relu' ,kernel_dim3= 2,kernel_dim2= 2)(Convolution3D_12) MaxPooling3D_23 = MaxPooling3D(pool_size= (2,2,2))(Convolution3D_13) BatchNormalization_23 = BatchNormalization()(MaxPooling3D_23) SpatialDropout3D_5 = SpatialDropout3D(p= 0.5)(BatchNormalization_23) GlobalMaxPooling3D_1 = GlobalMaxPooling3D()(SpatialDropout3D_5) Dense_1 = Dense(activation= 'relu' ,output_dim= 10)(GlobalMaxPooling3D_1) Dropout_14 = Dropout(p= 0.3)(Dense_1) Dense_6 = Dense(activation= 'relu' ,output_dim= 10)(Dropout_14) Dense_2 = Dense(activation= 'softmax' ,output_dim= 2)(Dense_6) return Model([Input_1],[Dense_2])
※引用
あなたは、ディープラーニングスタジオのソフトウェアプラットフォーム上でGUIをドラッグ&ドロップするというシンプルな動作で、プログラミングなしにモデル構築ができることがお分かりいただけたでしょう。
しかしこれだけではなく、ハイパーパラメータのチューニングもプログラミングすることなく行えるのです。
次のステップをご覧になり、ご自身の目でそれを確かめてください。
※引用終わり
Step-6: トレーニングとその結果
次に「HyperParametersタブ」をクリックして、バッチサイズが1にセットされていることを確認します。
ここが1より大きい数字になっているとGPUメモリに合わず、トレーニングが失敗してしまいます。
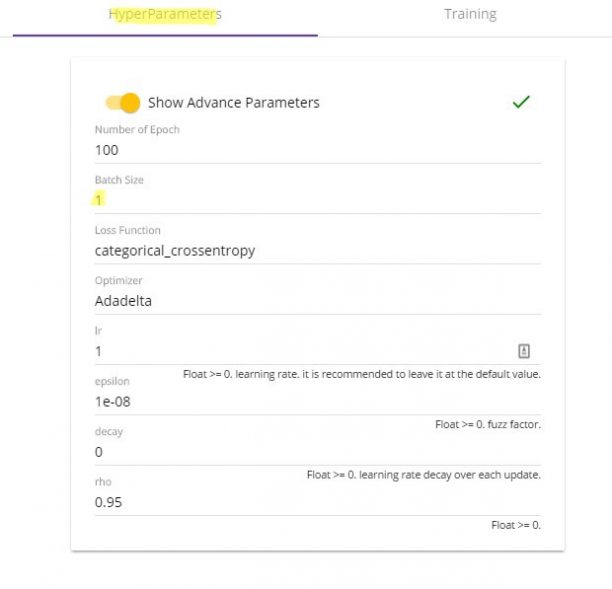
図6
最後に、Trainingタブに移動します。
インスタンスとしてGPU-K80を選択して「インスタンスを始める」をクリックします。
インスタンスが始まったら「トレーニングを始める」をクリックします。
データセットが大きく、また計算が必要となるため、トレーニングの速度は非常に遅くなることに留意してください。
2エポック(※1)試した後、検証セット上約0.58の損失を得ることができました。
1) エポック数とは、「一つの訓練データを何回繰り返して学習させるか」の数のことです。
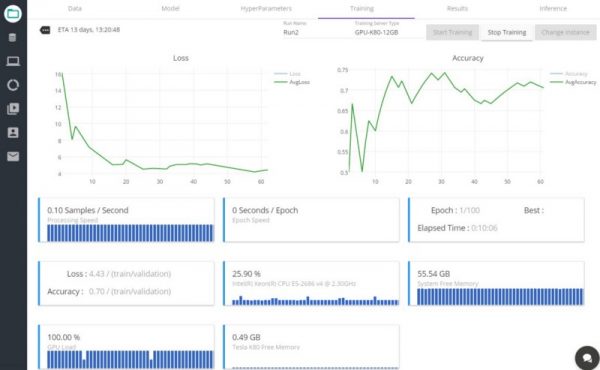
図7
モデルを作る前に、彼はCTスキャンデータセットに対していくつかの前処理をしています。
彼が作ったモデルに対する洞察や、前処理に関する全ての情報はこちらから確認できます。
デモの一連の流れは以上です。
ドラッグ&ドロップGUIを通じて、ディープラーニングのプロセスを単純化して加速させたこの新しいソフトウェアプラットフォームにより、
コーディングすることなくディープラーニングモデルを設計、トレーニング、デプロイできるということがお分かりいただけたと思います。
また、下記の参考にも目を通していただけると良いでしょう。
参考:
1、ディープラーニングについてもっと学びたい方はこちらをクリックしてください。
2、データサイエンティストFavio Vázquezをゲストに迎えた、Deep Cognition社主催のオンラインセミナー「ディープラーニングへのイントロダクション」を見てみたい方は、こちらをクリックしてください。
3、ディープラーニングスタジオを使用して、ディープラーニングモデルを作成した他の記事を読みたい方は、こちらをクリックしてください。
4、こちらのYouTubeでは、ディープラーニングスタジオを使用して、その他のモデル開発を行っています。






